希尔排序:插入排序的高效进阶之路
在数据处理的世界里,排序算法是基础且核心的存在。从简单直观的冒泡排序、插入排序,到高效灵活的快速排序、归并排序,每种算法都有其独特的设计思路与适用场景。希尔排序作为插入排序的优化升级版本,以“分组插入、逐步缩增量”的巧妙策略,打破了简单插入排序在无序数组中的性能瓶颈,成为兼顾简单性与效率的经典算法。它于1959年由美国计算机科学家唐纳德·希尔(Donald Shell)提出,因此得名希尔排序,又被称为“缩小增量排序”(Diminishing Increment Sort),至今仍在中等规模数据排序场景中发挥着重要作用。
一、希尔排序的核心思想:突破局限,分步优化
要理解希尔排序,首先要明确其优化的根源——简单插入排序的局限性。简单插入排序在处理近乎有序的数组时,效率极高,时间复杂度可接近O(n),但在面对完全无序的数组时,每次元素移动都只能跨越一个位置,最坏情况下时间复杂度会达到O(n²),当数据规模较大时,效率会大幅下降。
希尔排序的核心创新的就是引入“增量”(gap)概念,通过“先宏观调整,再微观整理”的策略,弥补了简单插入排序的不足。其核心思想可概括为三点:首先选取一个小于数组长度n的整数作为初始增量,将数组按增量分组,所有下标距离为增量倍数的元素归为一组;对每组分别执行简单插入排序,使每组内部变得有序;逐步缩小增量,重复分组与组内排序的过程,直到增量缩小为1;当增量为1时,整个数组被分为一组,此时数组已基本有序,再执行一次简单插入排序,即可完成最终排序。
这种策略的巧妙之处在于,大增量阶段可以让元素快速跨越多个位置,快速接近其最终排序位置,减少元素移动的次数;随着增量逐渐缩小,分组越来越多、每组元素越来越多,但此时数组已趋于有序,后续的插入排序效率会大幅提升,最终实现整体性能的优化。
二、希尔排序的执行流程:以实例读懂每一步
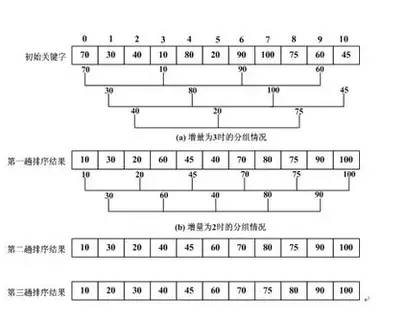
为了更直观地理解希尔排序的执行过程,我们以数组{49, 38, 65, 97, 76, 13, 27, 49, 55, 04}为例,采用最常用的“初始增量为n/2,每次减半”的增量序列,详细拆解每一趟排序的过程。
第一趟:初始增量gap = 5(n=10,10/2=5)
按增量5分组,数组被分为5组,每组包含2个元素,分组规则为下标相差5的元素为一组,分组结果如下:
组1:{49, 13}、组2:{38, 27}、组3:{65, 49}、组4:{97, 55}、组5:{76, 04}
对每组分别执行简单插入排序,排序后各组结果为:
组1:{13, 49}、组2:{27, 38}、组3:{49, 65}、组4:{55, 97}、组5:{04, 76}
将各组元素按原下标顺序拼接,得到第一趟排序结果:{13, 27, 49, 55, 04, 49, 38, 65, 97, 76}
第二趟:增量缩小为gap = 2(5/2=2,取整数)
按增量2分组,数组被分为2组,分组规则为下标相差2的元素为一组,分组结果如下:
组1:{13, 49, 04, 38, 97}、组2:{27, 55, 49, 65, 76}
对每组再次执行简单插入排序,排序后各组结果为:
组1:{04, 13, 38, 49, 97}、组2:{27, 49, 55, 65, 76}
拼接后得到第二趟排序结果:{04, 27, 13, 49, 38, 55, 49, 65, 97, 76}
第三趟:增量缩小为gap = 1(2/2=1)
此时增量为1,整个数组被分为一组,此时数组已基本有序,执行一次简单插入排序,最终得到有序数组:{04, 13, 27, 38, 49, 49, 55, 65, 76, 97}
从实例中可以看出,希尔排序通过多趟分组排序,逐步将数组调整为接近有序的状态,最后一次插入排序仅需少量移动即可完成排序,大幅提升了效率。
三、希尔排序的算法分析:性能、特点与增量选择
(一)时间复杂度
希尔排序的时间复杂度较为特殊,它并非固定值,而是依赖于增量序列的选择,这也是其性能分析的核心难点。目前尚未有统一的严格最优界,不同增量序列对应的时间复杂度存在差异:
1. 原始希尔增量(初始为n/2,每次减半):最坏时间复杂度为O(n²),实测性能虽优于简单插入排序,但在极端情况下仍接近O(n²);
2. Knuth增量(通过gap = gap * 3 + 1计算最大增量,再逐步缩小为gap = (gap-1)/3):实现简单且性能稳定,最坏时间复杂度约为O(n^(3/2));
3. 优化增量(如Hibbard增量、Ciura增量):可进一步提升性能,Ciura增量在实测中表现接近O(n^1.25)~O(n^1.5)之间。
总体而言,希尔排序的平均时间复杂度在O(n^1.3)左右,远优于简单插入排序的O(n²),但不及快速排序、归并排序的O(n log n)。
(二)空间复杂度
希尔排序属于原地排序算法,仅需要一个临时变量用于元素交换和插入,无需额外的大规模辅助空间,因此空间复杂度为O(1),这也是其重要优势之一,尤其适合内存受限的场景。
(三)稳定性
希尔排序是一种不稳定排序算法。虽然单趟插入排序是稳定的,但在多趟分组排序中,相同元素可能被分入不同组,在各组排序过程中,其相对位置可能被改变,最终导致排序后相同元素的相对顺序与原始顺序不一致。例如,原始数组中的两个49,在分组排序过程中可能被移动到不同位置,最终排序后无法保证其原始相对顺序。
(四)增量序列的选择原则
增量序列的选择直接影响希尔排序的性能,好的增量序列需满足两个核心原则:一是最后一个增量必须为1,确保最终能通过一次插入排序完成全局排序;二是尽量避免序列中的值(尤其是相邻值)互为倍数,防止分组重复,减少无效排序操作。实际应用中,Knuth增量因实现简单、性能稳定,是最常用的选择。
四、希尔排序的优缺点与应用场景
(一)优点
1. 效率优于简单插入排序,尤其对中等规模数组(n=1000~10000)表现优异,在无序数组中能大幅减少元素移动次数;
2. 原地排序,空间复杂度低(O(1)),无需额外内存,适合嵌入式系统、资源受限设备等场景;
3. 实现简单,代码简洁易懂,易于编码和调试,相较于快速排序、归并排序,学习成本更低。
(二)缺点
1. 性能受增量序列影响较大,不同增量序列的实现的性能差异明显,需要根据数据场景调整;
2. 非稳定排序,无法保证相同元素的相对顺序,不适合对排序稳定性有要求的场景;
3. 对大规模数据(n>10^5)的效率不及快速排序、归并排序等高级算法,不是大规模数据排序的最优选择。
(三)应用场景
1. 中等规模数据排序:当数据量在数百到数万之间时,希尔排序能兼顾效率与实现难度,表现出色;
2. 内存受限环境:如嵌入式系统、单片机等资源紧张的设备,其O(1)的空间复杂度具有明显优势;
3. 排序预处理:在复杂排序流程中,可先用希尔排序对数据进行预处理,使数据接近有序,再结合其他排序算法,提升整体排序效率;
4. 教学场景:作为插入排序的改进版本,希尔排序是理解“算法优化”思想的经典案例,适合用于数据结构与算法的教学实践。
五、希尔排序的代码实现(多语言示例)
希尔排序的代码实现核心围绕“增量控制”和“组内插入排序”展开,以下提供Python、C、Golang三种常用语言的实现示例,均采用Knuth增量序列,兼顾可读性与实用性。
(一)Python实现
def shell_sort(nums):
len_nums = len(nums)
# 增量d从len_nums/2开始,逐步减半,直到d>0(用while控制增量)
d = len_nums // 2
while d > 0:
# 遍历各组起始元素,从d开始到数组末尾(用while替代for)
i = d
while i < len_nums:
# 组内比较交换,从当前元素向前,步长为d(用while实现)
j = i
while j >= d and nums[j] < nums[j - d]:
# 交换元素,实现组内排序
temp = nums[j]
nums[j] = nums[j - d]
nums[j - d] = temp
j -= d
i += 1
# 增量减半
d = d // 2
return nums
# 测试示例
if __name__ == "__main__":
arr = [49, 38, 65, 97, 76, 13, 27, 49, 55, 4]
print("原始数组:", arr)
shell_sort(arr)
print("排序后数组:", arr)
(二)C语言实现
#include <stdio.h>
// 希尔排序函数(采用你指定的三层for循环格式,增量d从len/2开始,逐步减半)
void shellSort(int arr[], int len) {
// 第一层for循环:控制增量d,从len/2开始,每次减半,直到d>0
for(int d = len/2; d > 0; d /= 2) {
// 第二层for循环:遍历各组的起始元素,从d开始到数组末尾
for (int i = d; i < len; ++i) {
// 第三层for循环:组内比较交换,从当前元素向前,步长为d
for (int j = i; j >= d && arr[j] < arr[j - d]; j -= d) {
// 交换arr[j]和arr[j-d],实现组内插入排序
int temp = arr[j];
arr[j] = arr[j - d];
arr[j - d] = temp;
}
}
}
}
// 打印数组
void printArray(int arr[], int n) {
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
// 测试
int main() {
int arr[] = {49, 38, 65, 97, 76, 13, 27, 49, 55, 4};
int len = sizeof(arr) / sizeof(arr[0]);
printf("原始数组:");
printArray(arr, len);
shellSort(arr, len);
printf("排序后数组:");
printArray(arr, len);
return 0;
}
(三)Golang实现
package main
import "fmt"
// 希尔排序(采用增量d从len/2开始,逐步减半,统一格式)
func shellSort(nums []int) []int {
lenNums := len(nums)
// 第一层:控制增量d,从lenNums/2开始,逐步减半,直到d>0
for d := lenNums / 2; d > 0; d /= 2 {
// 第二层:遍历各组起始元素,从d开始到数组末尾
for i := d; i < lenNums; i++ {
// 第三层:组内比较交换,从当前元素向前,步长为d
for j := i; j >= d && nums[j] < nums[j - d]; j -= d {
// 交换元素
temp := nums[j]
nums[j] = nums[j - d]
nums[j - d] = temp
}
}
}
return nums
}
func main() {
arr := []int{49, 38, 65, 97, 76, 13, 27, 49, 55, 4}
fmt.Println("原始数组:", arr)
arr = shellSort(arr)
fmt.Println("排序后数组:", arr)
}
六、总结:希尔排序的价值与意义
希尔排序作为插入排序的改进版本,其核心价值在于“以空间换时间”的反向思维——不依赖额外辅助空间,而是通过巧妙的分组策略,让元素快速接近最终位置,从而提升排序效率。它没有快速排序的极致高效,也没有归并排序的稳定性,但凭借简单易实现、空间效率高的特点,在中等规模数据排序和资源受限场景中,始终占据着不可替代的位置。
从算法思想来看,希尔排序的“逐步细化”策略,为后续算法优化提供了重要思路——将复杂问题拆解为多个简单子问题,分步解决,最终实现整体优化。对于学习者而言,理解希尔排序的核心逻辑,不仅能掌握一种实用的排序算法,更能深刻体会“优化”的本质:不是推翻原有逻辑,而是找到原有逻辑的局限性,通过细节调整,实现性能的飞跃。
在如今大数据时代,虽然希尔排序不再是大规模数据排序的首选,但它依然是数据结构与算法领域的经典案例,其设计思想和优化思路,对理解更复杂的排序算法、提升编程思维,都具有重要的指导意义。